Energy-Efficient Scalable Multicore Architectures
Current Researchers: TBD;

Over the last decade, Moore’s Law has slowed, while Dennard Scaling has ended. The end of voltage scaling has made power dissipation the fundamental barrier to scaling computing performance across all platforms –from hand-held, embedded systems, to laptops, to servers, to datacenters.
This challenge, often called the power wall, is seen across the board. To meet power challenges, recent research has proposed various low-power techniques. Power-gating, for example, is an effective technique that powers off the under-utilized components to reduce static power consumption.
Dynamic voltage and frequency scaling (DVFS) is another technique that saves power by leveraging the application load to dynamically adjust voltage and frequency. The simultaneous use of various low-power techniques in one system can reduce more power consumption while creating several problems. For example, these low-power techniques can potentially conflict with each other if they are employed concurrently and make decisions at inappropriate times. These conflicts can even negatively affect performance and power savings.
In our research, we combine various power saving techniques while avoiding their shortcomings. The combination of different techniques leads to an explosion of design space. We further explore the use of machine learning to optimize the combined system.
1. TBD
M. Clark, A. Kodi, R. Bunescu and A. Louri, “LEAD: Learning-enabled Energy-Aware Dynamic Voltage/Frequency Scaling in NoCs,” to appear in Proceedings of the 55th Design Automation Conference (DAC), San Francisco, CA, 2018.
Network on Chips (NoCs) are the interconnect fabric of choice for multicore processors due to their superiority over traditional buses and crossbars in terms of scalability. While NoC’s offer several advantages, they still suffer from high static and dynamic power consumption. Dynamic Voltage and Frequency Scaling (DVFS) is a popular technique that allows dynamic energy to be saved, but it can potentially lead to loss in throughput. In this paper, we propose LEAD - Learning- enabled Energy-Aware Dynamic voltage/frequency scaling for NoC architectures wherein we use machine learning techniques to enable energy-performance trade-offs at reduced overhead cost. LEAD enables a proactive energy management strategy that relies on an offline trained regression model and provides a wide variety of voltage/frequency pairs (modes). LEAD groups each router and the router’s outgoing links locally into the same V/F domain, allowing energy management at a finer granularity without additional timing complications and overhead. Our simulation results using PARSEC and Splash-2 benchmarks on a 4 × 4 concentrated mesh architecture show an average dynamic energy savings of 17% with a minimal loss of 4% in throughput and no latency increase.
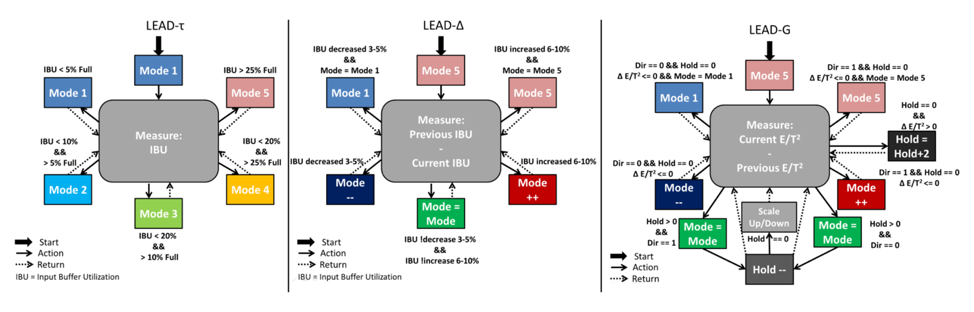
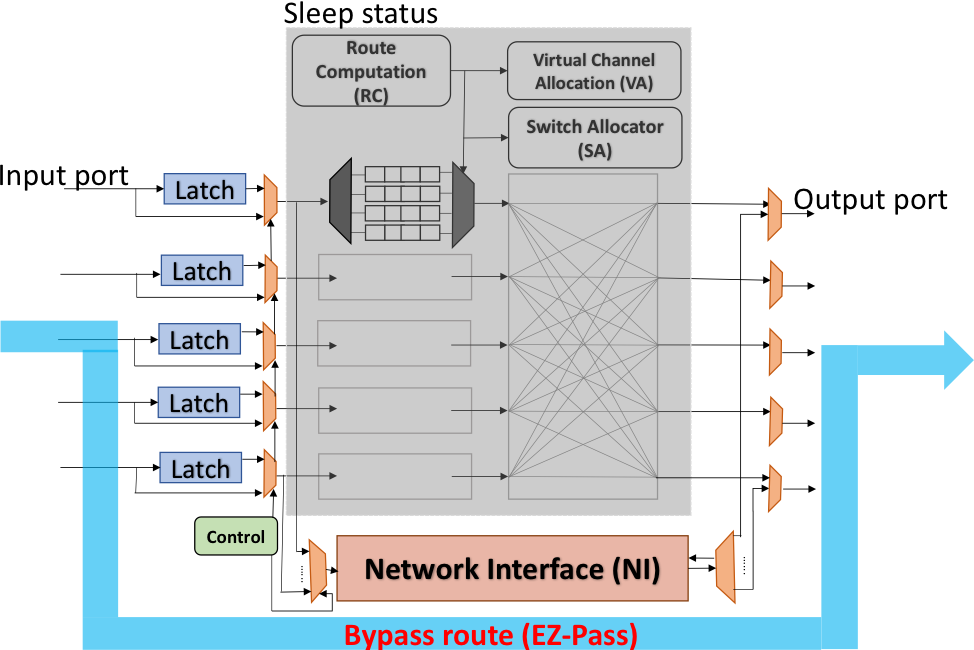
2. TBD
H. Zheng and A. Louri, “EZ-Pass: An Energy & Performance-Efficient Power-gating Router Architecture for Scalable NoCs,” in IEEE Computer Architecture Letters, vol. PP, no. 99, Dec. 2017.
With technology scaling into nanometer regime, static power is becoming the dominant factor in the overall power consumption of Network- on-Chips (NoCs). Static power can be reduced by powering off routers during consecutive idle time through power-gating techniques. However, power-gating techniques suffer from a large wake-up latency to wake up the powered-off routers. Recent research aims to improve the wake-up latency penalty by hiding it through early wake-up techniques. However, these techniques do not exploit the full advantage of power-gating due to the early wake-up. Consequently, they do not achieve significant power savings. In this paper, we propose an architecture called Easy Pass (EZ-Pass) router that remedies the large wake-up latency overheads while providing significant static power savings. The proposed architecture takes advantage of idle resources in the network interface to transmit packets without waking up the router. Additionally, the technique hides the wake-up latency by continuing to provide packet transmission during the wake-up phase. We use full system simulation to evaluate our EZ-Pass router on a 64-core NoC with a mesh topology using PARSEC benchmark suites. Our results show that the proposed router reduces static power by up to 31% and overall network latency by up to 32% as compared to early-wakeup optimized power-gating techniques.
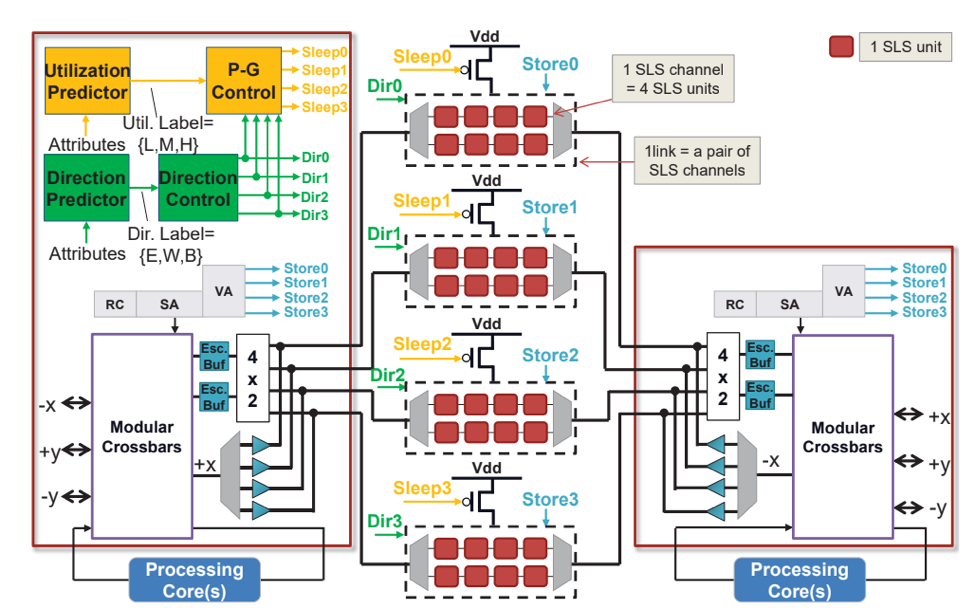
3. TBD
D. DiTomaso, A. Sikder, A. Kodi and A. Louri, “Machine learning enabled power-aware Network-on-Chip design,” in Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), 2017, Lausanne, 2017, pp. 1354-1359.
Although Network-on- Chips (NoCs) are fast becoming pervasive as the interconnect fabric for multicore architectures and systems-on- chips, they still suffer from excessive static and dynamic power consumption. High dynamic power consumption results from switching and storing data within routers/links while excess static power is consumed when routers and links are not utilized for communication and yet have to be powered up. In this paper, we propose LESSON (Learning Enabled Sleepy Storage Links and Routers in NoCs) to reduce both static and dynamic power consumption by power-gating the links and routers at low network utilization and moving the data storage from within the routers to the links at high network utilization. As the network utilization increases from low-to- high, to accommodate more traffic, we design the same channels to flow traffic in either direction, thereby avoiding complex routing or look-ahead wake-up algorithms. Machine learning algorithms predict when to power-gate the channels and routers and when to increase the channel bandwidths such that power savings are maximized while performance penalty is minimized. Our results show that we can improve total network power consumption when compared to conventional NoC buffer designs by 85.6% and when compared with aggressive NoC buffer designs by 31.7%. Our predictor shows marginal performance penalties and by dynamically changing the direction of the links, we can improve packet latency by 14%.